【Python】multiprocessing環境でのloggingについて
■multiprocessing環境ではFileHandlerを使ってはいけません!
OSのファイル書き込みの仕組み上、複数のプロセスが同じファイルに
ログデータを書き込もうとするとログファイルがぶっ壊れます。
RotatingFileHandler, TimedRotatingFileHandler等を使った日には
ローテーションのタイミングでエラーを吐きまくります。
これはPython公式にもしっかりと明記されています。
複数プロセスからの単一ファイルへのログ記録はサポートされません 。
なぜなら、複数のプロセスをまたいで単一のファイルへのアクセスを直列化する
標準の方法がPythonには存在しないからです。
■ではどのように対処すればよいのか?
対処法についても上記の公式ページにて紹介されています。
それがSocketHandlerを使う方法です。
別プロセスにてソケットサーバーを立て、そこに全てのログを
集約させることによって同時書き込みによるファイル破損を防ぎます。
ソケットサーバーのコードについても公式クックブックに記述されていますので、
そちらをベースにファイル書き込みまで行うプログラムを紹介します。
■サーバー側のプログラム
基本的にはこちらのコードのままとなります。
https://docs.python.org/ja/3/howto/logging-cookbook.html#network-logging
まずは全体像。
import pickle
import logging, logging.handlers
import socketserver
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
''' LogRecordバイナリを読み込んで処理する。 '''
# ロガーを保存しておく。
loggers = {}
def handle(self):
''' バイナリからLogRecordオブジェクトを作成し処理する。 '''
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
obj = self.unPickle(chunk)
record = logging.makeLogRecord(obj)
self.handleLogRecord(record)
def unPickle(self, data):
''' バイナリ化されたデータを元のオブジェクトに変換する。 '''
return pickle.loads(data)
def handleLogRecord(self, record):
''' LogRecordオブジェクトを処理する。 '''
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
# 公式コードに追加した部分。すでにロガーが存在していれば既存のものを使う。
if name in self.loggers:
logger = self.loggers[name]
else:
logger = logging.getLogger(name)
handler = logging.handlers.RotatingFileHandler(f'./{name}.log', 'a+', 1024, 7, encoding='UTF-8')
logger.addHandler(handler)
logger.propagate = True
self.loggers[name] = logger
logger.handle(record)
class LogRecordSocketReceiver(socketserver.ThreadingTCPServer):
''' ログを受け取るソケットサーバー。 '''
allow_reuse_address = True
def __init__(self, host='localhost', port=logging.handlers.DEFAULT_TCP_LOGGING_PORT, handler=LogRecordStreamHandler):
socketserver.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None
def serve_until_stopped(self):
''' ソケットが読み込み可能になるあまで待機する。 '''
import select
abort = 0
while not abort:
rd, wr, ex = select.select([self.socket.fileno()], [], [], self.timeout)
if rd:
self.handle_request()
abort = self.abort
def main():
tcpserver = LogRecordSocketReceiver()
print('About to start TCP server...')
tcpserver.serve_until_stopped()
if __name__ == '__main__':
main()公式とコードが変わっている部分は、LogRecordStreamHandlerにて
ロガー保存のためのloggers = {}が追加されているのと、
handleLogRecord()にて以下の部分が追加されています。
if name in self.loggers:
logger = self.loggers[name]
else:
logger = logging.getLogger(name)
handler = logging.handlers.RotatingFileHandler(f'./{name}.log', 'a+', 1024, 7, encoding='UTF-8')
logger.addHandler(handler)
logger.propagate = True
self.loggers[name] = logger
logger.handle(record)ここでは、送られてきたログをRotatingFileHandlerによって処理していま
ここで注意する点としては以下があります。
- 既にロガーにハンドラが設定されているのにaddHandlerを使ってはいけない
- 同じロガーがに複数のロガーが設定されることになるため、ログが重複します。
- ローテーションをすぐ起こすためにmax_sizeを1024Bに設定
- propagate(ログの伝播)はTrueにしておく
- 通信量を減らすためにこうしてます。細かい理由はのちほど説明します。
■クライアント側のプログラム
検証用として複数のプロセスで連続してログを送ることができる
LoggingTestクラスを作成します。
import sys
import os
import multiprocessing as mp
import logging, logging.handlers
from time import sleep
class LoggingTest:
''' マルチプロセス環境でのロギングの検証を行う。 '''
def start(self, name, number, count, to_file=False):
'''
numberの数だけプロセスを立ち上げ、それぞれのプロセス内で
nameで設定した名前のロガーを作成し、
'''
for n in range(number):
process = mp.Process(target=self.main, args=(name, n, count, to_file))
process.start()
def main(self, name, number, count, to_file=False):
''' 各プロセスが行う処理。countの数だけログをとる。 '''
pid = os.getpid()
logger = self.set_logger(name, to_file)
for i in range(count):
logger.debug(f'{number} {pid} {i:02d}')
sys.exit(0)
def set_logger(self, name, to_file=False):
''' ロガーを作成する。to_fileフラグでソケットサーバーに送るかその場でファイル作成するか選択する。 '''
logger = logging.getLogger(name)
logger.setLevel(logging.DEBUG)
if to_file == False:
handler = logging.handlers.SocketHandler('localhost', logging.handlers.DEFAULT_TCP_LOGGING_PORT)
# 通信量を減らすため、ここでの伝播は行わない。
logger.propagate = False
else:
handler = logging.handlers.RotatingFileHandler(f'./{name}.log', 'a+', 1024, 7, encoding='UTF-8')
logger.addHandler(handler)
return logger
if __name__ == '__main__':
pass指定した個数のプロセスを立ち上げることができ、
各プロセスが指定個数のログを連続出力します。
また、ソケットサーバーにログを送信するか、そのプロセスが
その場でファイル書き込みを行うか選択できます。
ここで、先ほどのpropagateについてですが、
こちらクライアント側ではFalseに設定しています。
例えば、以下のようなロギングがあった場合、
logger = logging.getLogger('test.app')
logger.debug('logger')loggerにpropagate=Trueが設定されていると、logger.debug()を
実行したときに、まずtset.appのハンドラの処理が行われます。
次に、testロガーにハンドラが設定されていた場合、伝播し処理されます。
このとき内部でLogRecordオブジェクトが作成されますが、そのオブジェクトが持つ、
ロガーのnameプロパティの値は'test'ではなく'test.app'のままになっています。
そのため本来ならば、testとtest.appロガーがそれぞれ1回ずつ
サーバーに送られるのが正しい動作ですが、test.appが2回送られることに
なってしまいます。
これを防ぎ、さらに通信量を減らすためにクライアント側では
伝播はさせず、サーバー側にまかせてしまおうということです。
■実験1 ファイルが壊れることを確認
ソケットサーバーを使わない場合、ファイルが壊れることを確認します。
3つのプロセスそれぞれで100回ロギングします。
to_fileフラグをTrueにし、ソケットサーバーを経由させないようにします。
if __name__ == '__main__':
test = LoggingTest()
test.start(name='test1', number=3, count=100, to_file=True)結果をみると、まずコンソールにはFileNotFoundErrorが
でていることに気づきます。ログを書こうとしたらほかのプロセスが
いつの間にかローテーションを行い書き込むファイルがなくなったという状況が
起きていることが分かります。
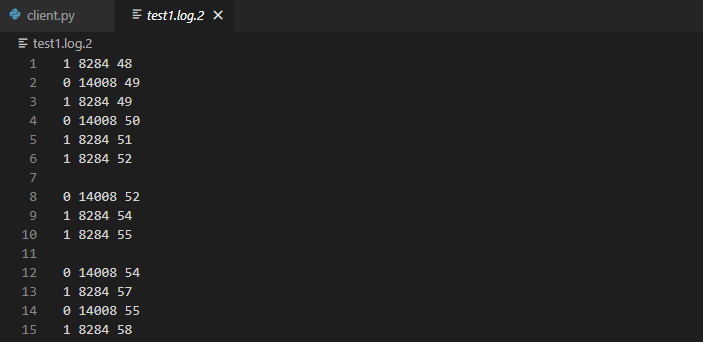
ログファイルの中身を見てみると、以下の画像のように
謎の改行が挿入されています。場合によっては、メッセージの
途中で改行が挿入されたりすることもあります。
■実験2 ソケットサーバーを使い正常動作することを確認
実験1と同じプロセス数、回数で、to_fileフラグをFalseにします。
if __name__ == '__main__':
test = LoggingTest()
test.start(name='test2', number=3, count=100, to_file=False)結果を見ると、特にエラーを出さず正常終了しました。
ログファイルの中身も特に異常は見られません。
■結論
ログは障害対応において重要な情報源ですので、
せめてそのログが信頼できるようにしなければなりません。
multiprocessingを使う場合のロギングは、ソケットサーバーを
用意する必要があるということを覚えておきましょう。