【機械学習】Tensorflowでオートエンコーダー – AutoEncoder
オートエンコーダーとは?
オートエンコーダとは、入力したデータのだいたいの特徴を抽出し、次元圧縮するモデルです。
これだけ聞くと、PCA(主成分分析)で良くね?と思われますが、
このモデルが広く使われるほど有用である理由が、その学習方法にあります。
オートエンコーダーは、ニューラルネットワークで次元削減した後のデータ、これを潜在変数Zとすると、
そのZからさらにニューラルネットワークを用いて元の次元数に復元し、
復元されたデータと元の入力データを比較しながら似るように学習していきます。
これで学習した後、未知データを入力したときに、
復元できるデータ → 学習時の入力データに似たデータ
復元できないデータ → 学習時にない異常なデータ
と考えることで異常検知をすることができます。
環境構築
Windows10を使っているのでAnacondaでpython環境を構築します。
python: 3.6.8
GPU: GTX1050
ライブラリ: numpy1.14, tensorflow-gpu, tensorboard, matplotlib, jupyter
numpyはそのままconda installやpip installするとtensorflow未対応の
最新バージョンが入ってしまうので、
conda install numpy=1.14 pip install numpy=1.14
等のようにバージョン指定してインストールしてください。
プログラムの構造
プログラム全体はここにあります。
https://github.com/mygod877/AutoEncoder/blob/master/AutoEncoder.ipynb
ライブラリのインポート等
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
import shutil
import sys
import matplotlib.pyplot as plt
import warnings
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
shutil.rmtree("../logs/AutoEncoder")
必要ライブラリをインポートしてください。
9-10行目はうっとおしいWarningを消すために書いています。
11行目はtensorBoardのデータを消しています。
ハイパーパラメータの設定
# 入力次元 X_n = 784 # Encoder入力 enc_n = [500, 300] enc_layer_n = len(enc_n) # Decoder入力 dec_n = [300, 500] dec_layer_n = len(dec_n) # 潜在変数Zの次元 Z_n = 20 # 学習回数 epoch_n = 10 # バッチサイズ batch_size = 100
入力データにはmnistを使うので28×28=784が入力次元です。
enc_n, dec_nは各ニューラルネットワークの層の入力次元をリストで渡します。
enc_layer_n, dec_layer_nが層の数です。
入力データの準備
mnist = input_data.read_data_sets("../MNIST_data", one_hot=True)
train_X = mnist.train.images
validation_X = mnist.validation.images
test_X = mnist.test.images
mnistデータセットを使用します。
70000枚の28×28pxの手書き数字の画像があり、そのうち、
55000枚をトレーニングデータ、
5000枚をバリデーションデータ、
10000枚をテストデータで分割します。
チューニングの仕方は以下の手順になります。
- トレーニングデータで学習
- バリデーションデータで性能評価
- ハイパーパラメータの調整
- トレーニングデータで学習
- バリデーションデータで性能評価
- 2と5を比較し、性能が良くなった方を採用
- 4-6を繰り返して最適なハイパーパラメータを探す
- テストデータで性能評価←モデル全体の性能
モデルアーキテクチャ
X = tf.placeholder(tf.float32, [None, X_n])
# Encoder
with tf.name_scope("Encoder"):
enc_w = []
enc_b = []
enc_h = []
for i, n in enumerate(enc_n):
input_shape = [X_n if i == 0 else enc_n[i - 1], enc_n[i]]
with tf.name_scope("Layer%02d" % (i + 1)):
enc_w.append(tf.Variable(tf.truncated_normal(input_shape, stddev=0.1)))
enc_b.append(tf.Variable(tf.truncated_normal([enc_n[i]], stddev=0.1)))
enc_h.append(tf.nn.relu(tf.matmul(X if i == 0 else enc_h[i - 1], enc_w[i]) + enc_b[i]))
# Z
with tf.name_scope("Z"):
Z_w = tf.Variable(tf.truncated_normal([enc_n[enc_layer_n - 1], Z_n], stddev=0.1))
Z_b = tf.Variable(tf.truncated_normal([Z_n], stddev=0.1))
Z = tf.nn.relu(tf.matmul(enc_h[enc_layer_n - 1], Z_w) + Z_b)
# Decoder
with tf.name_scope("Decoder"):
dec_w = []
dec_b = []
dec_h = []
for i, n in enumerate(dec_n):
input_shape = [Z_n if i == 0 else dec_n[i - 1], dec_n[i]]
with tf.name_scope("Layer%02d" % (i + 1)):
dec_w.append(tf.Variable(tf.truncated_normal(input_shape, stddev=0.1)))
dec_b.append(tf.Variable(tf.truncated_normal([dec_n[i]], stddev=0.1)))
dec_h.append(tf.nn.relu(tf.matmul(Z if i == 0 else dec_h[i - 1], dec_w[i]) + dec_b[i]))
# G
with tf.name_scope("G"):
G_w = tf.Variable(tf.truncated_normal([dec_n[dec_layer_n - 1], X_n], stddev=0.1))
G_b = tf.Variable(tf.truncated_normal([X_n], stddev=0.1))
G = tf.sigmoid(tf.matmul(dec_h[dec_layer_n - 1], G_w) + G_b)
# loss
with tf.name_scope("loss"):
loss = tf.nn.l2_loss(G - X)
# Optimizer
opt = tf.train.AdamOptimizer().minimize(loss)
以下がTensorBoardのモデル図となります。
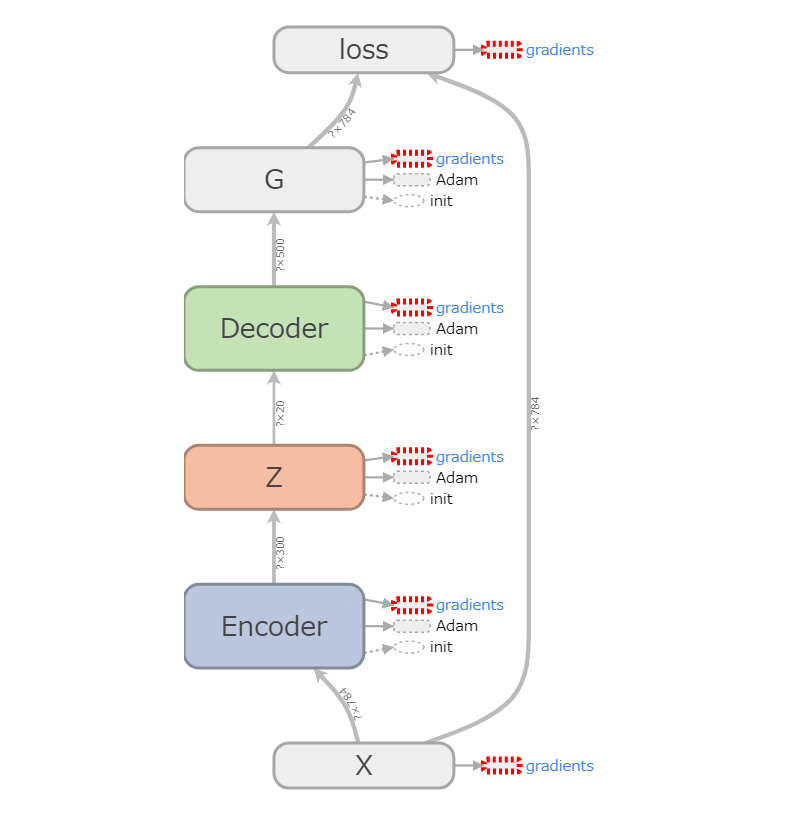
流れとしては以下の通りです。
- トレーニングデータXをEncoderに入力
- Encoderから潜在変数Zを抽出
- ZをDecoderに入力
- DecoderからGに入力し、画像を生成
- 生成画像GとXの差分からlossを計算
- lossを最小化するようにOptimizerが各重みを更新
セッション開始
sess = tf.Session()
sess.run(tf.initialize_all_variables())
writer = tf.summary.FileWriter('../logs/AutoEncoder', sess.graph)
tensorflowのセッション開始とtensorboardにグラフを書き込みます。
トレーニング
iteration_n = len(train_X) // batch_size
for epoch in range(epoch_n):
sff_X = np.random.permutation(train_X)
for iteration in range(iteration_n - 1):
batch = sff_X[batch_size * iteration:batch_size * (iteration + 1)]
sess.run(opt, feed_dict={X: batch})
train_loss = sess.run(loss, feed_dict={X: batch})
sys.stdout.write("\repoch: %d, loss: %.3f" % (epoch + 1, train_loss))
sys.stdout.flush()
ミニバッチ学習をしていきます。
トレーニングデータをbatch_sizeごとに分割したときの一つ分をミニバッチといいます。
本来ならば全トレーニングデータを入力仕切ってからOptimizerが重み更新するところを
ミニバッチを入力仕切ってから重み更新となるため、更新頻度を上げることができます。
この時、ミニバッチを1回入力することをイテレーションと数え、
トレーニングデータ分をすべて1回ずつ入力仕切ることをエポックと数えます。
トレーニングデータ55000枚、batch_sizeが100で数えると、
ミニバッチの数は550個となるため、1エポックあたり550イテレーションとなります。
性能評価
score = sess.run(loss, feed_dict={X: test_X}) / batch_size
print(score)
generate_images = sess.run(G, feed_dict={X: test_X})
plt.figure()
plt.subplot(1, 2, 1)
plt.title("X")
plt.imshow(test_X[0].reshape(28, 28))
plt.subplot(1, 2, 2)
plt.title("G")
plt.imshow(generate_images[0].reshape(28, 28))
バリデーションデータでハイパーパラメータチューニングをしてから
テストデータで性能評価するのが正しい流れなのですが、今回は省略します。